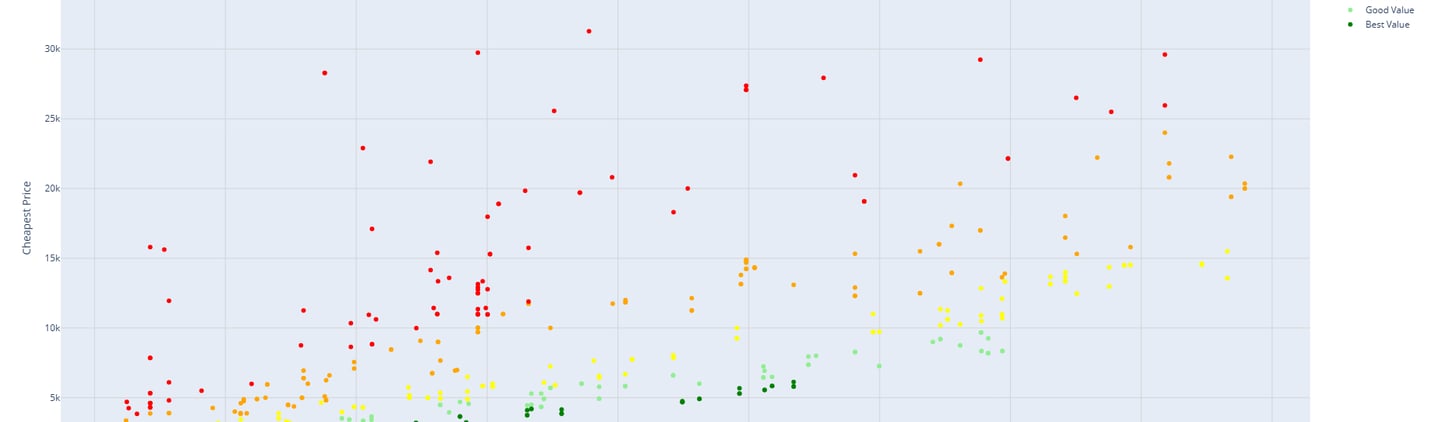
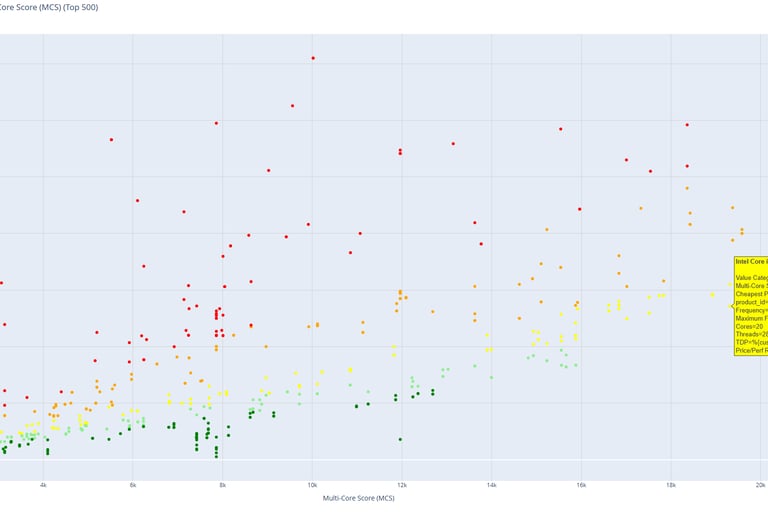
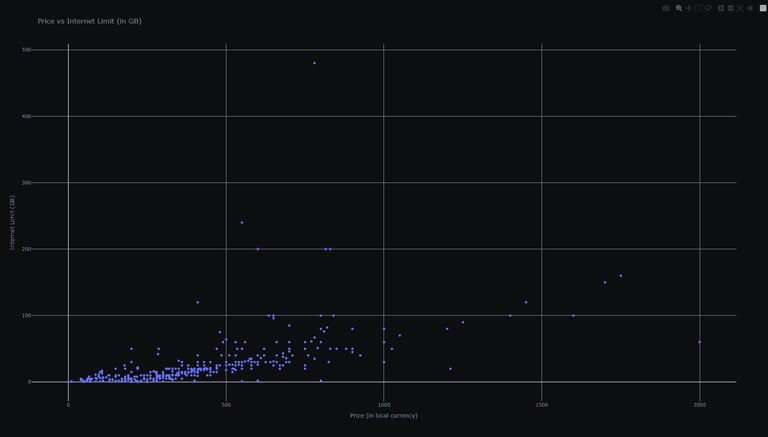
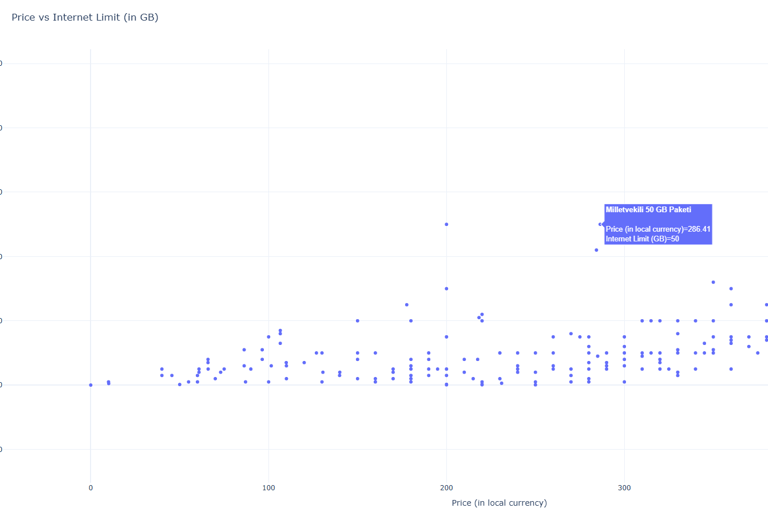
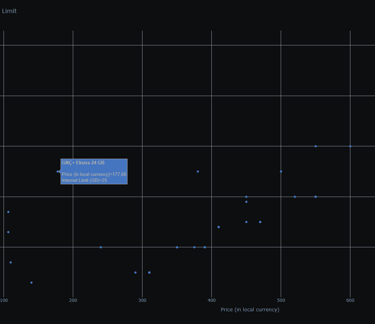
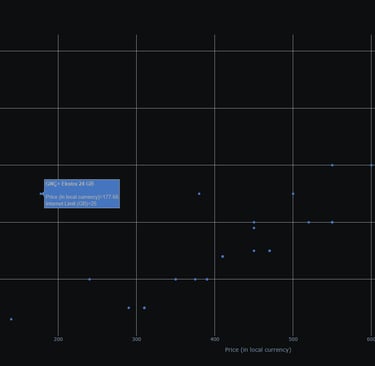
Price to Performance CPU Scatter
Estimating price basket item weights
Try to estimate TÜİK price basket items weights
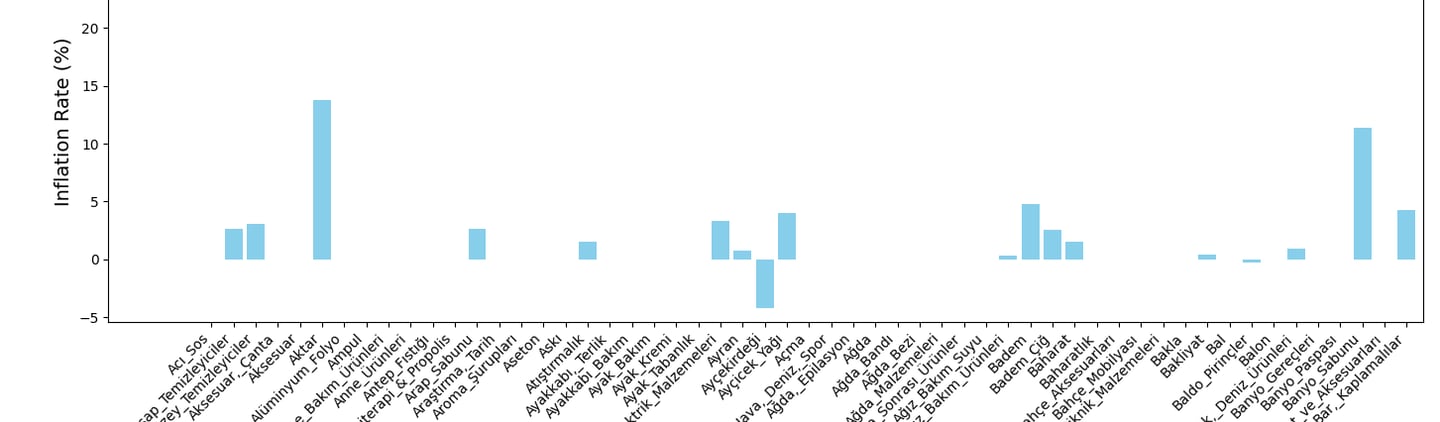
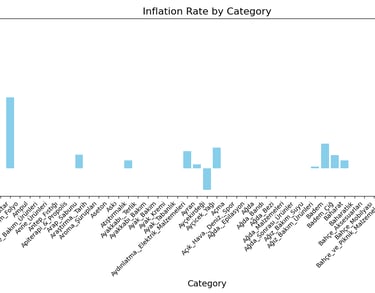
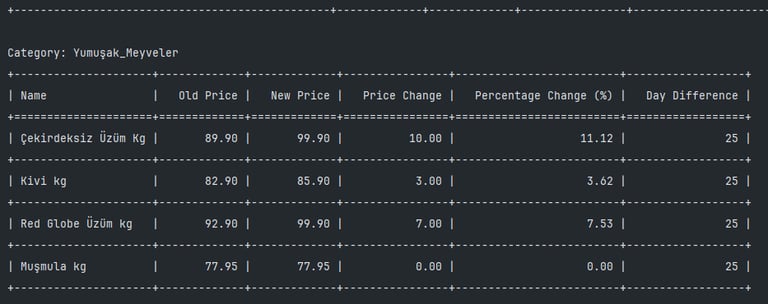
Issue 1: We need to give weights to items, currently each item has weight of 1.0.
Issue 2: Currently item count is more than 20.000 but it is not sufficient.
Issue 3: Need to add more price data such as flight prices, mobile data plans, clothes, rent costs etc.
Idea: calculate price/performance per item than measure the change. Then separate items by 3 levels (Low, mid and high).
Idea: Use TUIK methodology to see results.
More things need to be added...
Note: Still in progress...

Turkcell package prices
LLM chat with FR
Using local LLM (LLama 3.1) to get information about companies financial reports and more...





LLM based sentiment analysis.
Local LLM based sentiment analysis.
XLS → XLSX → JSON convertor
Using GROK api for given ticker.
Using LM STUDIO for running local LLM for given ticker.
A convertor for files downloaded into useful form, thus improving file naming.

Access to CBRT data from python
Statstics.py
Printer for some useful statistics for all tickers in the stock market.
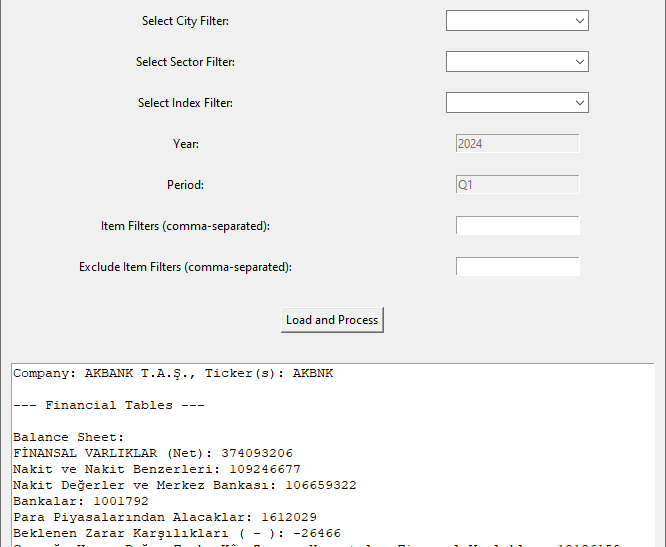
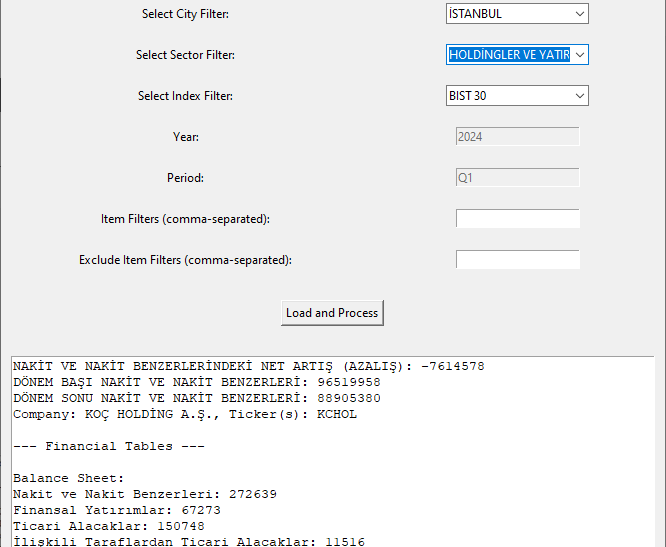
FR downloader GUI
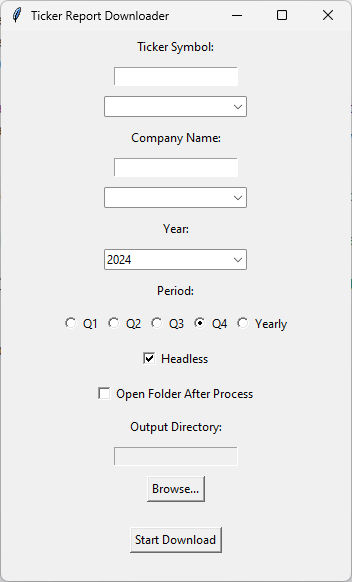
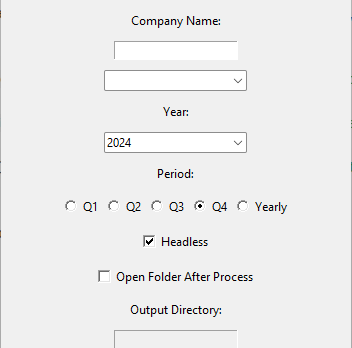
This code creates a Tkinter-based GUI application for downloading financial reports from a specified website, allowing users to input a ticker symbol or company name, select a year and period, and choose additional options such as headless browsing and opening the output folder after download, with synchronized fields and default settings to streamline the process.
Information about code
15138 chars
335 lines
24.07.2024
FR downloader for all avalible companies
This project involves automating the process of downloading financial reports for companies based on their ticker symbols and company names. The project leverages web scraping to interact with the KAP (Kamuyu Aydınlatma Platformu) website to retrieve these reports. The reports are then managed, tracked, and organized to handle different periods and years of data, with error handling and status tracking implemented throughout the process.
The goal of your project is to automate the collection and management of financial reports for companies from the KAP (Kamuyu Aydınlatma Platformu) website. Specifically, the objectives are:
Automated Report Retrieval: Efficiently download financial reports for companies based on their ticker symbols or names for specified years and periods, minimizing manual intervention.
Data Management: Maintain an organized tracking system to monitor which reports have been downloaded, including handling cases where reports are missing or there are issues with ticker names.
Error Handling and Reporting: Implement robust error handling to manage and log failures or issues encountered during the download process, and provide clear reporting on the status of each company's report.
File Organization: Ensure downloaded reports are properly stored, including extracting ZIP files if necessary, and managing temporary files effectively.
Overall, the project aims to streamline the process of gathering and organizing financial data, enhancing efficiency and accuracy in report collection.
Information about code
ticker_report_downlader.py
11543 chars
263 lines
25.07.2024
report_manger.py
5036 chars
109 lines
25.07.2024


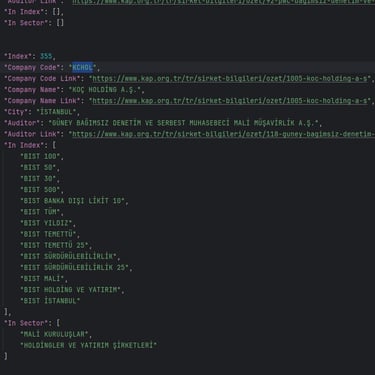
KAP ticker data
The provided Python script is designed to scrape and process financial data from the KAP (Kamuyu Aydınlatma Platformu) website. It performs the following steps:
Fetches HTML Content: Retrieves HTML content from three different URLs related to company information, indices, and sectors using the requests library.
Parses HTML Content: Utilizes BeautifulSoup to parse the HTML and extract relevant information based on specific CSS classes.
Extracts Data:
Companies: Extracts details such as company code, name, city, and auditor.
Indices: Extracts index information for companies.
Sectors: Extracts sector-specific company data.
Saves Data: Saves the extracted data to JSON files.
Groups Data: Groups company-related data by company code for both indices and sectors.
Merges Data: Merges company data with indices and sector information.
Saves Merged Data: Outputs the combined data into a final JSON file.Metni buraya yazın...
Information about code
All_2.py
8369 chars
225 lines
22.07.2024
SPK report saver
This script scrapes financial bulletins from the Turkish Capital Markets Board (SPK) website, downloads PDF files, and manages them by renaming and tracking their status. It handles pagination, extracts bulletin details, and maintains a log of downloaded files to avoid duplicates.